Top-pick rate is the metric that pays. Five UK outdoor brands prove why mention rate isn't enough.
Last week I ran five UK outdoor operators through Invisible Competitor: Atom Packs, Alpkit, Hilltrek, Aiguille Alpine, and Jöttnar. Five well-known brands. Five "Strong AI Referral" statuses. Five 100% mention rate reports, AI named every one of them in every conversation we tested across ChatGPT, Claude, and Gemini.
By the metric most AI visibility tools sell on, all five are winning.
They're not. Top-pick rate, the share of conversations where AI returns you as the #1 referral, ranged from 20% to 73% across the five. That's a 53-point gap on a roster where every brand passed the "AI knows you exist" test. And it's the gap that decides where buyers actually go.
This is what the data showed, and what it teaches about which metric to track when AI engines are the place your customers ask their first question.
Why mention rate is the warm-up
Mention rate is straightforward: out of N AI conversations testing your category, how many named you anywhere in the answer?
Top-pick rate is sharper: how many returned you as the explicit top recommendation?
Both numbers come out of the same query batch. The relationship between them tells you something specific. High mention, low top-pick means AI is aware of you, knows your category, can list you when prompted, but defaults to someone else when a buyer asks "who should I buy from?" That's the position most established brands are in.
The reason this matters: AI buyers don't read every word of an answer. They take the top-line referral and move on. The brand named first gets the click rate that used to belong to the #1 Google result. The brands further down get vanishingly little.
So when an "AI visibility" dashboard tells you you're at 80% mention rate, what it's really saying is: AI is at the warm-up stage of selling for you. The cold-start problem is solved. The conversion question, does AI pick you when a buyer asks who to buy from? is a different question, and it's the one revenue depends on.
This is why AI Referral Score combines mention rate, top-pick rate, and technical readiness in a weighted index, rather than reporting any one in isolation. And it's why, when looking at scan data, top-pick rate is the first number worth reading.
The five brands
| Brand | Top-pick | Mention | Tech readiness | Where it loses |
|---|---|---|---|---|
| Aiguille Alpine (Cumbria) | 73% | 100% | 65% | Broad category queries, Rab takes "best mountaineering rucksack" |
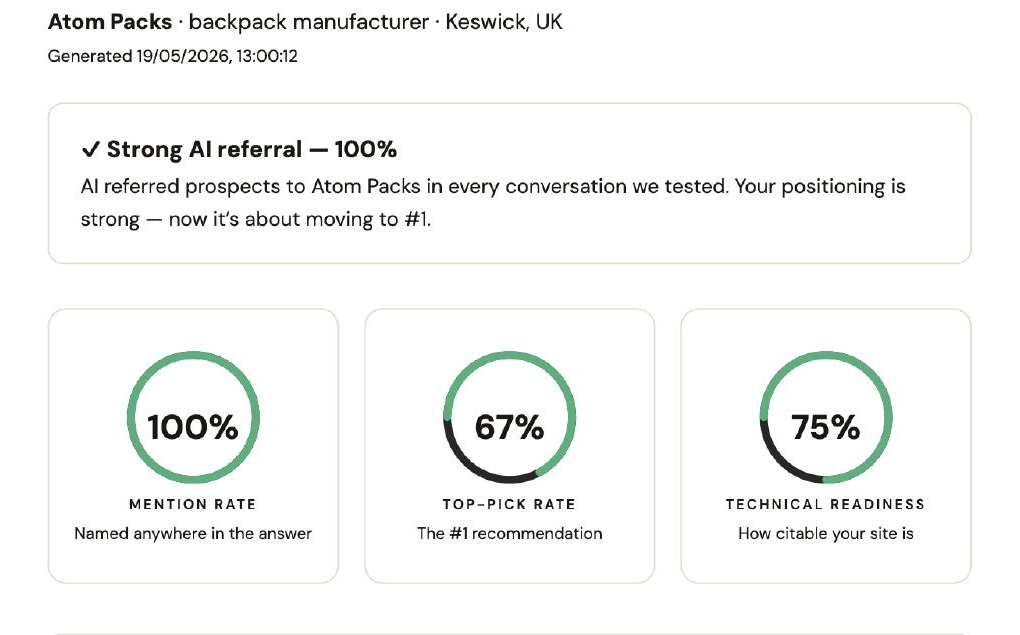
| Atom Packs (Keswick) | 67% | 100% | 75% | US ultralight queries, Outdoor Vitals, Pa'lante, Zpacks |
| Hilltrek (Aboyne) | 60% | 100% | 10% | Hunting clothing queries, Jack Pyke takes the niche |
| Alpkit (Nottingham) | 53% | 100% | 65% | "British Patagonia alternative", Finisterre wins |
| Jöttnar (Cardiff) | 20% | 100% | 82% | Almost every category query, Rab wins 3 of 5 |

Aiguille Alpine, 73% top-pick (the winner)
A 40-year-old climbing pack workshop in Staveley, Cumbria. Founded 1987. Family-scale operation that hand-builds alpine rucksacks.
Aiguille Alpine took top pick on Gemini and was named in every ChatGPT answer. On the query "British alternative to Osprey climbing packs," Claude and Gemini both put them above Berghaus, Karrimor, Rab, and Montane. What AI rewards them for is precisely what they are: a small, specific, long-established UK manufacturer of one thing, in one place. The entity is unambiguous. The story is the story.
Where they slip is on broad category queries. "Best mountaineering rucksack manufacturers UK" went to Rab on Claude, because Rab is the obvious answer when the query gets less specific. The narrower the question, the more Aiguille Alpine wins. The broader the question, the more they lose to the category leader. That's a normal small-manufacturer pattern, and it's the pattern worth defending.
Atom Packs, 67% top-pick
A custom ultralight backpack maker in Keswick. Cult following among UK long-distance hikers.
Atom Packs was the top pick on both ChatGPT and Gemini, named in 4/5 answers on each. Look at where the losses cluster: they're all on the queries without UK signal in them.
The wins are on "custom ultralight backpack makers UK" and "British alternative to Osprey for thru hiking." Both queries explicitly anchor the question in the UK. AI hears the geographic constraint and answers from UK-anchored content. Atom Packs wins.
The losses are on "best value frameless hiking pack 30L" and "best custom hiking pack for PCT." Neither query carries UK signal. The first is geography-neutral. The second carries US signal (the PCT is the Pacific Crest Trail). On those, AI defaults to whichever brand has the heaviest global content footprint for that specific need. For ultralight hiking gear, that footprint sits in US ultralight forums, YouTube channels, gear-review sites, and thru-hiker blogs, so AI picks Outdoor Vitals Shadowlight Carbon 60, Osprey Talon 33, Gossamer Gear Kumo 36. Different US-leaning brands on different engines, but the pattern is consistent: no UK signal in the query, no UK brand in the answer.
This is the discoverability lever, and it's actually a fix you can work. AI doesn't decide what's UK based on who's asking; it decides based on what's in the query plus what UK signal exists in the content it indexes. For the geography-neutral queries that matter to you, two playbooks: defend the UK-specific queries hard (already winning), and pick a couple of category-level queries you actually want to own, then build the UK-anchored evidence for them. UK editor reviews. Specific UK trail use cases. Named UK long-distance hikers using the product. Get that content into the ecosystem AI reads, and the geography-neutral queries start producing UK results.
Hilltrek, 60% top-pick (the paradox)
A handmade Ventile jacket workshop in Aboyne, Royal Deeside. Thirty years. Small team.
Hilltrek was top pick across all three engines. Their technical readiness score was 10/100. No schema markup. No llms.txt file. No FAQ section. Entity clarity 5/10. Content structure 5/10. The site reads, by every conventional "you must do this for AI search" checklist, like a brand that should be invisible. It isn't. It's top pick.
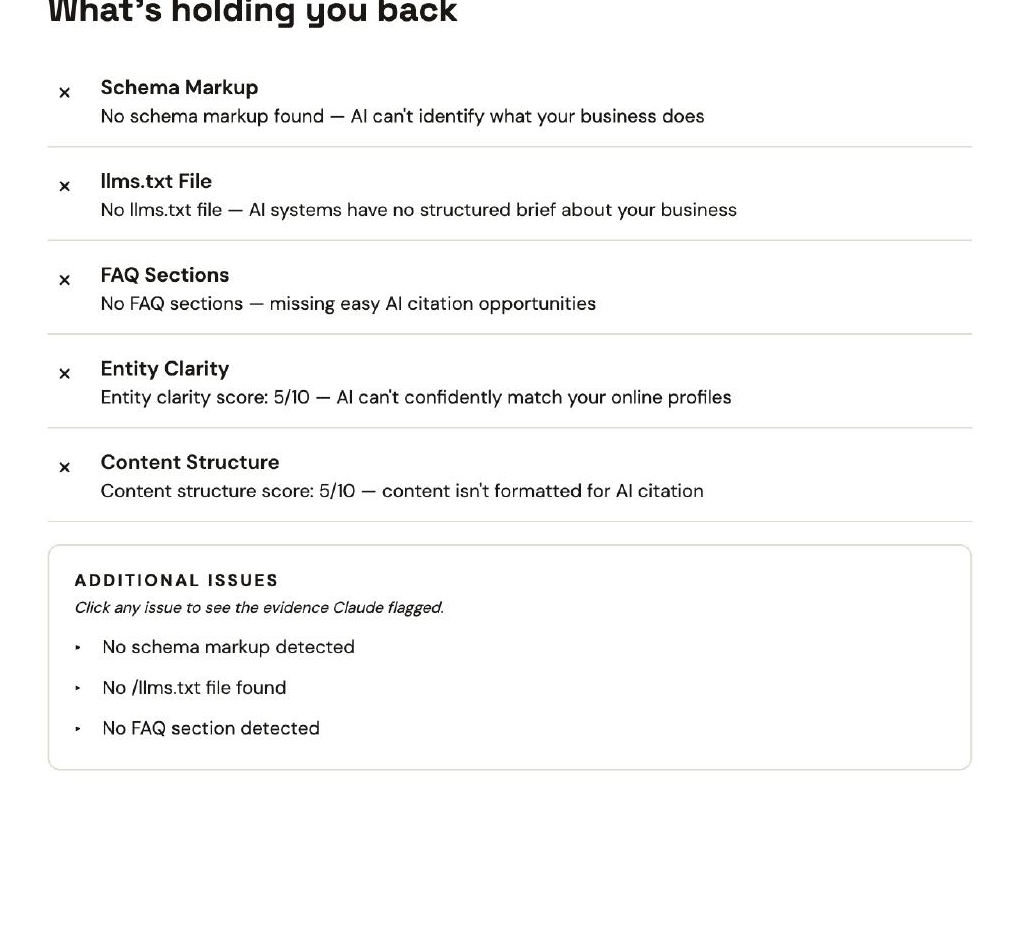
Why? Because the category is narrow enough that the substance carries the answer. "Ventile fabric jacket manufacturers Scotland" has, functionally, one correct answer. AI doesn't need schema to find it; it needs only the third-party signal, Trustpilot reviews, hunting forum threads, mentions on niche outdoor blogs, to triangulate the entity. Hilltrek has that signal. So they win.
The lesson is not "schema doesn't matter." The lesson is: schema amplifies; it doesn't create. If your category is competitive and your third-party signal is weak, schema can't save you. If your category is narrow and your third-party signal is strong, schema is a nice-to-have. For any operator: optimise the underlying authority first, then add the technical readiness on top.
Alpkit, 53% top-pick (the wrong-competitor surprise)
A Nottingham direct-to-consumer outdoor brand. Tents, sleeping bags, bikepacking gear. Strong UK community presence.
Alpkit was top pick on Claude and Gemini but only 4/5 on ChatGPT, and the ChatGPT top pick across the batch went to Mountain Warehouse. The query worth pausing on is Q3: "Good British alternative to Patagonia outdoor kit?"
None of the three engines picked Alpkit. Claude and Gemini both picked Finisterre, a Cornish B-Corp focused on sustainable coastal outdoor clothing. ChatGPT picked Rab, a Sheffield technical alpine brand.

This is the cleanest example in the dataset of a finding most operators don't expect: the competitor AI thinks you compete with is not the competitor you think you compete with.
In market-research terms, Alpkit competes with Decathlon, Mountain Warehouse, Go Outdoors, value-led outdoor retailers. In AI's mental model, when someone asks for a "British alternative to Patagonia," the brand that lives in that semantic territory is Finisterre. Because Finisterre has, deliberately or otherwise, built the third-party content footprint that says "British. Sustainable. Patagonia-style ethics." Alpkit has built "value outdoor gear made by people who actually climb." Different territory. AI matches the territory, not the category.
This is the single most actionable insight in the dataset. If you don't know what queries you're trying to own, AI will assign you to queries based on what the rest of the internet says about you. The fix is positioning work, not technical work.
Jöttnar, 20% top-pick (the named-but-not-chosen)
A Cardiff-based technical outdoor clothing brand founded by former Royal Marines mountain leaders. Premium pricing. Strong climbing community credibility.
Jöttnar had the highest technical readiness score of the five (82/100). 100% mention rate. And they lost on four of five queries. Rab won three of those four. On Q1, "best technical down jacket for mountaineering UK", all three AI engines named Rab as top pick. None named Jöttnar.
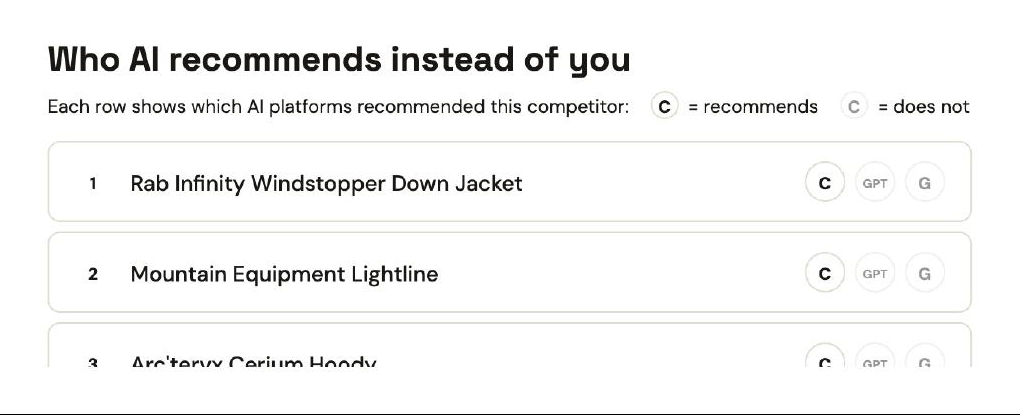
This is the hardest position to fix. Jöttnar's homepage tells a strong founder story, has clean structure, has working schema. The site is technically ready in the way the technical-readiness audit measures. But the wider internet, the third-party content AI weights heavily for "best of" referrals, is dominated by Rab. Rab has forty more years of magazine reviews, expedition sponsorships, retailer specs sheets, and forum mentions than Jöttnar.
AI's referral isn't a popularity contest, but it is a triangulation across signals. Jöttnar earns the mention because the signal exists, they're a credible UK technical brand and the AI knows it. They lose the top pick because the weight of evidence still points to Rab.
Fixing this is the slowest of the five fixes. Schema won't move the number. Technical readiness won't move the number. What moves the number is earning new third-party signal, sponsored expeditions, technical editor reviews, named professional users, that AI can read and weight. That's a 12-24 month play, not a 90-day one.
Four patterns across the five
Mention rate ceilings out at the top. All five scans showed 100% mention. The metric stops telling you anything useful past 70-80%. Top-pick rate is where the actual variance lives, and where the revenue is.
AI engines disagree, constantly. Same brand, same query, different winner. The brand winning on Claude often loses on ChatGPT. Each engine weights signals differently, pulls from different training subsets, and applies different recency rules. There is no such thing as "AI optimisation" in aggregate. You optimise per engine, and you measure per engine.
Technical readiness is necessary but not sufficient. Schema, llms.txt, FAQ markup, content structure, these matter, but they amplify existing authority; they don't create it. Hilltrek wins with no schema because their category is narrow and their substance is strong. Jöttnar loses with strong schema because the third-party signal weight still favours Rab. If you're spending money on technical-readiness fixes without addressing the underlying authority gap, you're polishing the wrong lever.
The competitor AI names is often not the competitor you track. Alpkit doesn't compete with Finisterre in any market-research sense. Atom Packs doesn't compete with Pa'lante Packs in any UK retail sense. But AI puts them in those competitive sets because the internet's content about each brand puts them there. The most valuable output of an AI Referral Benchmark isn't a number, it's the list of competitors AI is referring buyers to instead of you. Some of those names will surprise you. Those are the brands actually taking your AI-sourced revenue.
What to do
If the headline number on your AI visibility dashboard is mention rate, replace it. The version that matters is top-pick rate, measured per engine, on the queries your buyers actually phrase.
When you find the gap, and the gap will exist; it existed for all five of these brands, the order to work the levers is:
First, identify the queries you actually want to own. Not categories. Queries. "British alternative to Patagonia" is a query. "Outdoor gear" is not.
Second, audit the third-party signal supporting each query. Reviews, named expert mentions, expedition coverage, retailer pages. If the signal is thin, the technical fixes won't carry the weight.
Third, add the technical readiness layer, schema, llms.txt, FAQ markup, entity clarity. Understand it as amplification, not substitution.
Fourth, track per-engine. ChatGPT, Claude, and Gemini disagree. Optimising for the average means optimising for nothing.
The full version of this analysis, across the up to 100 customer phrasings the AI Referral Benchmark tests, with every competitor AI is referring named and prioritised, is the work we do per brand. The free AI Referral Check tests two queries and gives you the headline numbers. Either one will show you the gap. The Benchmark tells you which lever to pull first.
Run the free AI Referral Check, 3 questions across ChatGPT, Claude, and Gemini, your score in two minutes. Start your check →